I have moved to a new position at the Ohio State University. If you need to reach me, please contact me at the following email address: williamson.413@osu.edu
Research
My research objective has been to develop algorithms that analyze, process, and extract meaningful information from auditory scenes. Auditory scenes contain valuable information, including speech, source location, music, and emergency alerts such as a passing police car. Humans with normal hearing naturally analyze auditory scenes, but computer systems and humans with hearing impairments struggle to perform this task. My goal as a researcher is to develop algorithms that address this problem in realistic and challenging auditory environments.
Generally speaking, I am interested in the following broad research areas:
- Speech Processing (separation, recognition, identification, etc.)
- Audio Scene Analysis
- Music Information Retrieval
- Machine Learning/Artificial Intelligence
- Deep Learning
- Signal Processing
- Robotics
Projects
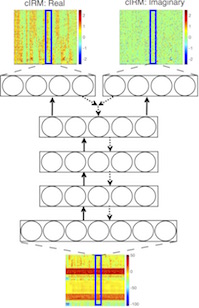
Complex Ratio Masking for Speech Separation
Speech separation systems usually operate on the short-time Fourier transform (STFT) of noisy speech, and enhance only the magnitude spectrum while leaving the phase spectrum unchanged. This is done because there was a belief that the phase spectrum is unimportant for speech enhancement. Recent studies, however, suggest that phase is important for perceptual quality, leading some researchers to consider magnitude and phase spec- trum enhancements. We present a supervised monaural speech separation approach that simultaneously enhances the magni- tude and phase spectra by operating in the complex domain. Our approach uses a deep neural network to estimate the real and imaginary components of the ideal ratio mask defined in the complex domain. We report separation results for the pro- posed method and compare them to related systems. The proposed approach improves over other methods when evaluated with sev- eral objective metrics, including the perceptual evaluation of speech quality (PESQ), and a listening test where subjects prefer the proposed approach with at least a 69% rate.
Estimating NMF Activations
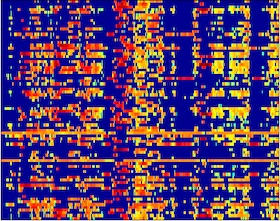
As a means of speech separation, time-frequency masking applies a gain function to the time-frequency representation of noisy speech. On the other hand, nonnegative matrix factorization (NMF) addresses separation by linearly combining basis vectors from speech and noise models to approximate noisy speech. We present an approach for improving the perceptual quality of speech separated from background noise at low signal-to-noise ratios. An ideal ratio mask is estimated, which separates speech from noise with reasonable sound quality. A deep neural network then approximates clean speech by estimating activation weights from the ratio-masked speech, where the weights linearly combine elements from a NMF speech model. Systematic comparisons show that the proposed algorithm achieves higher speech quality than related masking and NMF methods.
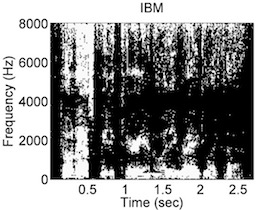
Binary Mask Reconstruction
This study proposes an approach to improve the perceptual quality of speech separated by binary masking through the use of reconstruction in the time-frequency domain. Non-negative matrix factorization and sparse reconstruction approaches are investigated, both using a linear combination of basis vectors to represent a signal. In this approach, the short-time Fourier transform (STFT) of separated speech is represented as a linear combination of STFTs from a clean speech dictionary. Binary masking for separation is performed using deep neural networks or Bayesian classifiers. The perceptual evaluation of speech quality, which is a standard objective speech quality measure, is used to evaluate the performance of the proposed approach. The results show that the proposed techniques improve the perceptual quality of binary masked speech, and outperform traditional time-frequency reconstruction approaches.
Song Similarity
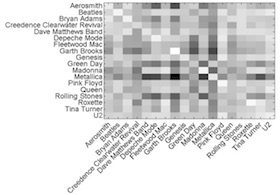
This project explores a method that uses a computer algorithm to assess song similarity, where the degree of similarity is based solely on the sound waveform of various songs. By extracting acoustic features that represent timbre, or sound quality, similarity is assessed by comparing the quantitative distance between features. The similarity between songs is also visually revealed through a computer interface, where songs that are similar are clustered together and dissimilar sounded songs are placed further apart. This visualization can serve as a means for recommending music based on similarities. Human subjects have also rated the similarity between songs by using a predefined rating system. A final evaluation of this algorithm consists of comparing the data generated from human subjects to the data generated by the automatic song similarity algorithm.
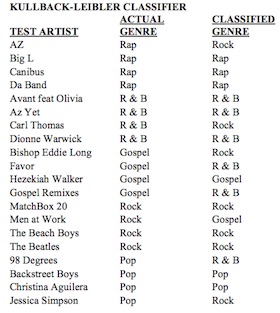
Musical Artist and Genre Classification
Our initial research task was to successfully classify the genre or artist of a musical piece. A supervised-learning approach was employed to successfully classify the artist or genre of a group of songs or an individual song, respectively. Our genre classifier was able to correctly classify 60% of the testing songs, whereas 72% of the testing models were classified as the correct artist.