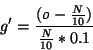The MostFrequentWords level (level 1) learns which words are currently occurring frequently in the stream of text passing through it, without needing to refer to a database of pre-indexed documents. It will trap any word that occurs frequently, including non-discriminators, such as ``and,'' ``or,'' and ``not.'' The intention is for this layer to select a small number of common terms; in our experiments, this level contains 150 nodes, each of which is associated with a single term.
Nodes in this level do not directly record how many times their words
occur. Instead, each occurrence of a word in the text stream
increases the excitement of its associated node. To control growth,
at each processing step
the excitement of the nodes in level 1 decreases by
![]() where r is the rate of decay per word passed
into the sieve and b is a base rate for decay. In short, for
every 100 words presented to the sieve, the excitement of every node
is decreased by b.
where r is the rate of decay per word passed
into the sieve and b is a base rate for decay. In short, for
every 100 words presented to the sieve, the excitement of every node
is decreased by b.
The desired effect is that the excitement of a node will be related to the frequency of occurrence of its corresponding word in recent texts. More precisely, node activation levels are characterized by a threshold of frequency, the ``rate goal'' g, 0 < g < 1, representing the percentage occurrence of a term at which the excitement of that term's associated node should increase. If a word occurs with a frequency of g, its node will tend to maintain the same level of excitement. If a word occurs with a frequency less than g, then its node will decay more than it is excited, and over time, its excitement will decrease. If a word occurs with a frequency greater than g, the opposite occurs: its node will be excited more than it decays, and its excitement level will tend to increase.
When a word enters level 1, WordSieve does one of two things, depending on whether there is already a corresponding node for it in level 1.
The proper operation of this level depends on g. If g is too low, then too many terms will have increasing values in level one, and the network will be unable to distinguish the ones occurring frequently. If g is too high, then the words will decay too fast, resulting in the decay of even the frequently occurring words. The correct value of g depends on the distribution of word frequencies in the incoming text stream. Level 1 continuously adjusts the value of g to keep the excitement levels of about 10% of the nodes increasing, and the rest decreasing. After every document, g is reset to a new value g', given by the following equation.
In this equation, o is the number of nodes with excitement values greater than the initial value given to the nodes when they are assigned to a word, and N is the number of nodes in level 1.
The result is that level 1 can identify an approximation of the most frequently occurring words in the stream of text, without keeping track of all the words occurring and without keeping a database of the documents which have been accessed. In return for this, WordSieve sacrifices absolute precision and complete determinism. Because of the probabilistic element in the algorithm, the system will produce slightly different values each time it is run. However, as will be shown later, it is sufficiently precise that the system as a whole produces reliably similar results each time it is run.