To date programming languages remain the most effective way to communicate with a computer. In fact, a language is an elegant way to communicate—humans have developed and refined languages for hundreds of years for communication. Human languages have reached a high level of sophistication and artistry. Computer languages, on the other hand, are (still) utilitarian. Part of the reason is the need for computer languages to be unambiguous, which is in turn dictated by the current limitations of software and hardware technologies.
If you talk to most computer scientists they will argue for computer languages that are as close to mathematical descriptions of algorithms as possible. Computer scientists tend to have a predilection for languages that utilize a minimal set of constructs, which is often equated with a certain “elegance”. This is a different elegance from the kind you find in natural languages—this kind of elegance is a direct descendent of the elegance you find in math and a consequence of scientists' fascination with “Occam Razor”.
Computers are no longer the tools only for scientists and engineers. So, one could argue in favor of computer languages that are not necessarily rooted in math, but are designed to make tasks for specific types of users easier to express. For example, imagine a language that allows you to talk about scores, tones, chords, etc. Musicians would be at home using such a language to interact with computers, rather than having to use, say Scheme. Such languages are called “domain-specific languages.” A good example of a language that is specific to a domain and that has proved to be extremely popular is SQL.
We could go on and on discussing the relative merits of different languages, but there is one inescapable fact: we need a tool to translate a language into a form that a computer can understand. The need for such a tool is obvious. Computer hardware is usually designed to understand very low-level simple instructions for the purposes of making it widely usable. The tool that carries out this translation is a compiler. Indeed, a compiler is responsible for instilling meaning into the constructs of a language. In this way, compilation is at the heart of computing.
In this course we will study compilation techniques for procedural languages. What is the difference between procedural and declarative languages? Why would you prefer one to the other? Almost all contemporary computer hardware implement procedural architectures. This means that irrespective of the language you start with, at some point in the translation process the compiler must make the transition to procedural instructions. Often the compilers will make this transition sooner in the translation process than later. Gaining a good understanding of compilation techniques is essential to understanding the link between software and hardware, and hence between software and its performance.
In its simplest form a compiler translates a source program into a target program. Typically the source language is a programming language such as Fortran, C++, Java, or ML. The target language is usually the instruction set of a computer system. This does not always need to be the case.
The basic compilation technology has been around since the 1950s when Fortran was developed, along with a Fortran compiler. If all you care about is correctness of translation then the technology is well established and widely available. Things get interesting when you care not only about correctness but also performance.
The definition of performance can vary with the context. Very often performance means running time of an application. Sometimes it can also refer to the memory footprint, especially when memory requirements of the computation exceed the available main memory. It is often the case that decreasing an application's memory footprint also improves its runtime performance. Why? Almost all current research in language translation, i.e., compilation, is concerned with improving performance.
We can ask the following question: What are the obstacles to achieving maximal performance? We need to understand what we mean by “maximal performance” and what prevents an application from achieving that maximal performance.
One way to improve performance of an application is parallel processing. It is obvious that if we are able to execute parts of an application concurrently on multiple processors then we can potentially gain in runtime performance. If the multiple processors also bring their own main memories then this provides us a way of accommodating larger amounts of data in memory.
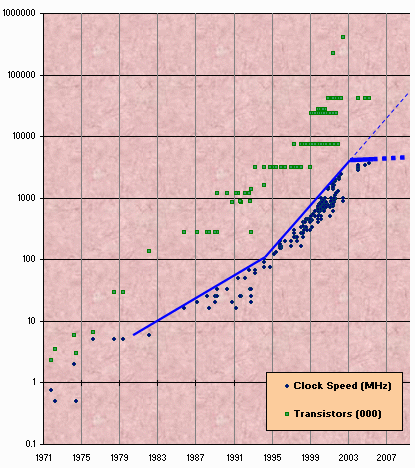
There is another reason parallel processing is of increasing interest—CPU clock wall.
The above graph was published in an article by Herb Sutter. It is interesting to note that after sustained exponential growth the clock frequencies have suddenly flattened. An exponential growth would have meant the current processors being somewhere around 10-20 GHz. The current highest-speed processors are no more than 4 GHz. As a result even mainstream processors now have multiple cores (multiple identical CPUs) on a single chip.
Of course, one form or another of parallelism has existed for years, even decades, now. What is new is that parallelism now pervades the entire hierarchy of computational units, from the single chip up to wide-area computational grids. This pervasiveness of parallelism introduces several challenges on how to program these highly complex systems.
The pervasiveness of parallelism poses several challenges. The two main issues from the perspective of writing, or generating, parallel programs are the amount of parallelism in an application and the locality. The amount of parallelism is a measure of how many computations can be executed in parallel without changing the meaning of the program. “Locality” refers to the quick availability of data when it is needed. The issue of locality comes up at several levels, including registers, cache memory, as well as main memory when the several independent machines cooperate to execute a task.
The technology developed for automatic parallelization over the past several years has been quite successful in discovering and extracting parallelism, but the success in maintaining good locality has been far less spectacular. Additionally, several other challenges remain. Some of the open issues include:
We will cover the following topics in this course, although not necessarily in this order.